

大規模開発にそなえてRails + EC2環境をEKSへ移行する

SREチーム所属のvaru3です。

noteではこの数年サービス規模が急成長し、現在では開発チームが開発に同時に携わる体制が敷かれるようになりました。元々noteはEC2上でRuby on Railsを実行するモノリシックなアプリケーションだったのですが、フロントエンドとバックエンドを分割し、さらに機能ごとにアプリケーションが必要というケースも増えてきました。
そこで、弊社ではnoteをコンテナ基盤(EKS)へと移行することが計画されました。
今回は弊社が運営する一部のサービスをEC2からEKSへと移行する検証を行い、実際に運用してみた知見を紹介します。
※ 社内LTでの発表内容を改めてインタビューし、再編した内容になります。
noteをEKSに移行する理由
noteをコンテナ基盤に移行する理由は、いわゆるマイクロサービス化を見据えたためと言えます(※)。noteでは先述の通り、バックエンドはRuby on Rails、フロントエンドはNuxt.jsをベースにして機能開発を行っています。最近では別のアプリケーションと通信をしたり、BFF(Backend for Frontend)が必要というケースも増えてきました。
このような小さな機能を従来のように、EC2でサーバを立てアプリケーションを実行する方法はマシンリソースもオーバーヘッドが増え、それぞれのアプリケーションごとにデプロイ手法やスケーリング手法を考えなければいけないため非効率です。EKS等のオーケストレーションツールを用いてコンテナを実行させれば、通信はクラスタ内で行われますし、デプロイやスケールアウトもクラスタ側で制御できるので、これらの諸問題が解決できると考えました。

デプロイについてはRailsにおける従来の手法だと、少々複雑な手順が必要になります。具体的には、Capistranoを用いて各サーバにアクセスしてソースコードを配布して、bundle installでGemをインストールし、アセットプリコンパイルして、UnicornやPumaを実行をします。
一方で、コンテナ基盤を用いた場合は、コンテナをビルドし、コンテナをデプロイするというシンプルなワークフローとなります。またデプロイにはBlue-Greenデプロイやカナリアデプロイという手法も使うことができるので、より安全にアプリケーションのデプロイを行うことができると考えました。
さらにスケールアウトの点では、EC2上でアプリケーションを立ち上げるよりもコンテナを立ち上げる方が圧倒的に高速です。瞬間的なアクセス増や、何かの起因でマシンリソースが枯渇しそうな場合には即時に対処することができるのではないかと考えました。

オーケストレーションツールの選定は、SREチームのリーダーである飯野さんに検証を行っていただきました。
最初はECSの選択肢も考えたそうですが、構築の自由度が少ない点と、Fargateを用いた場合の料金コストが高い点が懸念でした。ECSでは、コンテナ間通信やファイルのマウントにServiceDiscoveryやEFSなどのAWSリソースを作成することが必要で、各ECSサービスごとにAWSリソースを管理しなければならないため、EKS(Kubernetes)よりも自由度が低い点がありました。
最終的に、運用まで見据えた時に「EKSのnamespaceごとにアプリケーションを区切り、各チームごとに自由に開発してもらう」という方針が良いのではないかという点と、AWSのIAMユーザー(及びAWS SSO)とKubernetesのRBACを紐付けることができるaws-authの登場により、より柔軟な権限制御画できるようになったため、移行先としてEKSの方が適しているという判断になりました。
Railsを用いたモノリシックなWebアプリケーションにおいてはECSが適している
個人的にはRuby on Railsを用いたモノリシックなWebアプリケーションにおいてはECSが適していると考えています。今回の要件では複数開発チームが機能ごとに同じクラスタ内でアプリケーションを実行する、という要件を考慮した技術選択となりました。
実際に弊社の別のサービスではECS上で動いているものもありますし、便利に使っています。
このような技術選定は開発規模やチームの運用体制なども考慮されるという学びがありました。また、Kubernetes自体は何度か運用した経験はあるのですが、もちろん大変な部分も多くあり一筋縄ではいかないので、SREチームが盤石であることや、開発エンジニアへKubernetesを布教し学習コストをかけていく覚悟が必要だなと個人的には思っています。
Deploymentごとに操作権限を制御をする運用
EKSへの移行は同時にRailsのアプリケーションをコンテナで実行することになります。コンテナでのアプリケーションの実行はEC2上で実行する場合と異なる部分があるため、開発の運用意識を変える必要もあります。
その中でもサーバに入って直接、コマンドで処理を実行していたような運用は注意が必要です。弊社ではコンテナに入って直接操作するのは非推奨としています。

コンテナの操作がしたい場合は、AWS SSOやIAMユーザーの権限によってアクセス制御をするようにしました。
「DBに接続する」「Railsコンソールを使う」などの特定の操作のみしか実行できないPodを用意しておいてそのPodにExecできるユーザーを絞るようにしました。そうすることで、安全なインフラ運用が可能になります。EKSはAWSのIAMロールが利用できるため、権限管理がしやすいというメリットがありました。
操作権限については、弊社でもまだまだ検証段階で、各チームの誰が何を操作できればいいのかをより柔軟に制御できる方法を試行錯誤中です。
ログの扱いには注意が必要
コンテナでは、ログの取り扱いについても注意が必要です。基本的にはCloudWatch LogsやDatadog等の外部サービスと連携して保持します。
「RailsやNGINXのログは正常だけれど、Podが再起動を繰り返す事象」が発生することも。この場合は、メモリの枯渇だったり、ネットワークのヘルスチェックの失敗だったり、ノード側が原因のこともあります。
障害が発生したときの切り分けで、アプリケーション側(Pod)のエラーなのか、ノード側のエラーなのかを見極めなければなりません。
ローリングアップデートは常に最新のコミットを用いる
EKSの運用として注意すべきなのは、デプロイ時の切り戻しについてです。
EKSデプロイメントの制御で一つ前の状態に戻すことが可能です。
この機能を用いると「障害の切り戻しはPodの切り戻しですべて解決できそう」と思うかもしれません。しかし、コード以外の変更を行ったときには問題が発生するケースがあります。

例えば、DBのカラム変更などのマイグレーション後に障害が発生した場合、切り戻すとDBの不整合が発生してしまいます。
この場合、Podを切り戻すのではなく再デプロイする必要があります。
「フロントエンドサーバで障害発生したときは、Podを切り戻す」という運用ルールにすることも考えられますが、オペレーションが複数あるのは混乱の原因になります。以上のことから弊社では、常に切り戻す場合でも常に最新のコミットを含めてデプロイする方針としています。
バッチ処理はタイムゾーンに注意
今回の作業で時間がかかったのは、バッチサーバの移行でした。
移行時に一時的にバッチを止めるため「バッチを止めるとどこに影響するのか」を調べる必要があり、各エンジニアチームにコードの調査や実証をしてもらいました。
バッチ移行で注意しなければならなかったのはのは、EKSのタイムゾーンの仕様でした。
EKSではCronJobのタイムゾーンがUTCしか設定できませんでした。PodのタイムゾーンはJST、EKSのタイムゾーンはUTCということを考慮して、CronJobを設定する必要があります。
「1時間おきに実行する」などの定期実行なら問題はないのですが、「月末に実行する」などの期間指定のバッチ処理は注意が必要でした。
CodePipeline / CodeBuildの導入
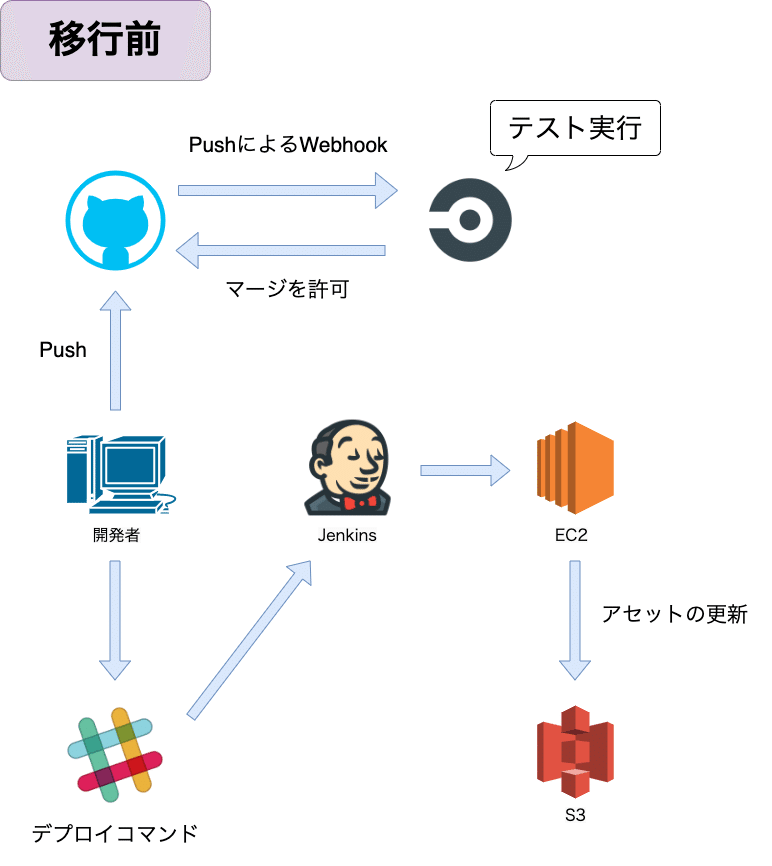

EKSの移行と同時に、デプロイもJenkinsからCodePipelineに移行しました。CodePipelineは弊社としても初めての導入になります。
CodePipelineはワークフローを直感的に組むことができ、実行環境のスペックなども柔軟に設定することが可能です。様々なカスタムコンテナやVPC上でも実行できるため、noteの一部ビルドやデプロイ処理も順次移行していく予定です。
おわりに
今回のEKS移行では、各エンジニアチームに大変お世話になりました。インフラ部分だけでなくアプリケーション側の改修が必要だったため、SREチームだけではEKSへの移行は完遂できませんでした。
今後、note自体もEKSへ移設するには、開発チーム全体が密になって連携していく必要があることを改めて実感しました。
これから大きな苦労は予想されますが、得られる恩恵も大きなものになるでしょう。「次はnote全体をコンテナ化していくぞ!!」ということで現在も準備を進めています。
各開発チームと協力して、障害のないようにしっかり進めていきたいと思います。
▼noteを一緒に作りませんか?
▼エンジニアの紹介記事
Text by megaya