
noteのデータ基盤チームとは?4つの開発軸とアーキテクチャを紹介

==============================
■データ基盤チームとは
PVやアクセスログなどのデータを活用できる仕組みを社内に提供するチーム。データによって意思決定や施策提案ができるように、有用なデータを蓄積する基盤の開発を主に行っている。インフラの設計 / 構築、サーバサイド、フロントエンドなど広範囲な知識が求められるチームでもある。
==============================
▲開発チームの全体図
エンジニアリングマネージャーの福井さんが聞き手役となり、リーダーの森さんに「データ基盤チームは何を開発しているのか?」「どんな技術を使っているのか?」などチームの紹介をしていただきました。
※ この記事のチーム編成は2021年10月時点の状況です

福井 烈(ふくい たけし) / エンジニアリングマネージャー
ジークレストやガンホー・オンライン・エンターテイメントを経て2015年にnoteに入社。サービス黎明期からnoteの開発に携わり、データ基盤や会計などを担当。現在はエンジニアリングマネージャーとして、開発チームの統括や組織編成などを行う。note / Twitter

森 豪基(もり ごうき) / データ基盤チームリーダー
新卒でバッファローに入社し、ハードウェア系開発を担当したのち、Web業界に転職。カヤックの子会社でCTOを経験したあとにnoteに2020年に入社。開発基盤チームのリーダーとしてチームをまとめつつ、自身も開発を行っている。
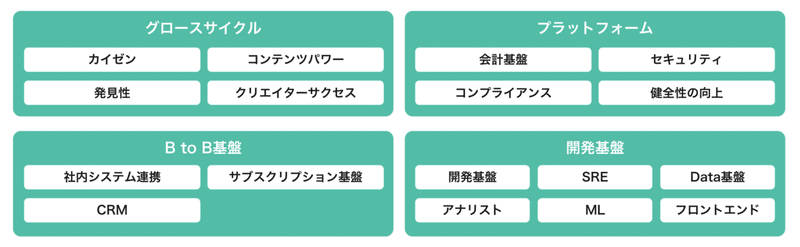
4つの軸:「データレイク」「データマート」「ターゲティング基盤」「ダッシュボード基盤」
福井:では最初に、データ基盤チームとして具体的に取り組んでいる開発を教えてください。
森:大きくわけて4つの開発軸があります。
・note内の整形されていないローデータを集積する「データレイク」
・データレイクから目的別に利用しやすい形にした「データマート」
・特定条件から簡単にデータを抽出できる「ターゲティング基盤」
・noteのクリエイターがよりデータを活用しやすくするための「ダッシュボード基盤」
チームとしてこれらの開発を並行して進めています。
福井:ちなみに今って何人のチームでしたっけ?
森:今は5人です。データレイクに2人、データマート1人、ダッシュボード基盤が1人、ターゲティング基盤は僕が兼務しながら進めています。(※ 2021年10月時点)
福井:noteの規模感からするとだいぶ少ない印象がありますね。エンジニアの人数って足りてますか?
森:やらなきゃいけないことは多いので人は増やしたいところですが、採用は慎重に進めたいとは思っています。理由は2つあって、1つはデータ量が多いため設計をしっかりと行いたいという点です。一度作ってしまうと手戻しが難しいため、時間をかけて要件定義をしてから開発を進めています。2つ目はエンジニアだけでなく、PM視点も必要だからです。データを活用する側からの意見を取り入れつつ進めていきたいので、PMの採用ペースと足並みを揃えられたらいいなと。
福井:たしかに慎重に進めていきたいですね。数年後にアーキテクチャを変えるとなっても、データ量的に移行自体が大変ですし。
森:技術選定やアーキテクチャの選択も、どれくらい先まで保守運用するかを見極めなければならないのは難しいポイントです。設計は汎用的にする方がいいことは間違いないのですが、汎用的にしすぎると特定の検索でデータが扱いづらいということも起こりえるので。
福井:数年前に僕もデータレイク周りの開発をしていたのでよくわかります。今は僕が作った部分も改修してもらっているので、本当に感謝しかありません(笑)
フロントエンドで数値をとるためのトラッキング部分も作り直していますよね?
森:そちらも進めています。今、トラッキングを取得する場合はコードを埋め込む必要があります。そのため、新規にメトリクスを取得するときに漏れがあったり、デグレが発生したりすることがたまにあるんですよね。こういった人為的なミスをなくせるように、サービス全体をトラッキングしてメトリクスが取得できるように改修していっています。
福井:いや、本当にありがたい(笑)
主な技術スタックやアーキテクチャは?
福井:では次に、データ基盤チームの技術スタックやアーキテクチャについて教えていただいてよろしいでしょうか?
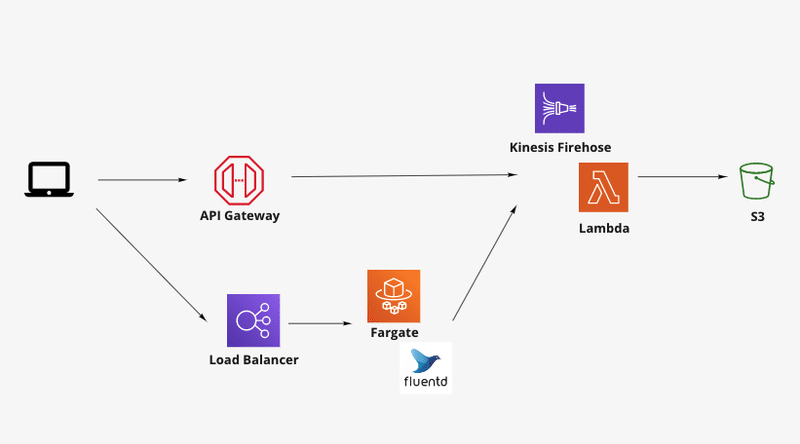
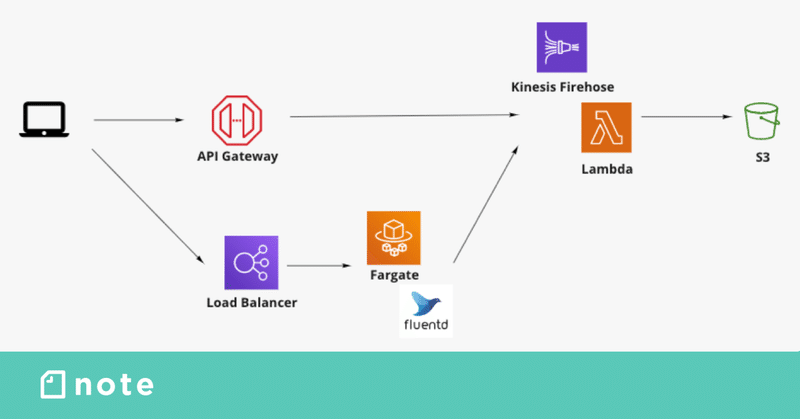
森:データレイクは主にS3にデータで保存し、機能ごとに取得して使用していきます。将来的にはAmazon Kinesis Data FirehoseからLambdaを介してDocumentDBにエクスポートし、AWS AppSyncで取得するという方法もあるかもしれないですね。
福井:なるほど。S3に入れたものを使う場合は、開発する機能に適した形で各ストレージに入れていくイメージでしょうか?
森:そうですね、レスポンスが求められるものに関してはキャッシュのような形でストレージに保存することもあります。Athenaは制限がけっこう厳しいので、開発のメインはS3に入れたデータになります。逆にアナリストやエンジニアが分析などに使う場合は、アクセス量も少なく、速度もネックにならないため、Athenaからデータを引いてもらうようにしています。
福井:ちょっと気になるところで言うと、DocumentDBを選択した意図ってなにかあるんでしょうか?メジャーどころで言えばDynamoDBも候補としてあがるのかなと思いまして。
森:DynamoDBももちろん検討しましたが、集計がちょっと弱いというのがネックだったんです。取得の月日が固定で決まっていれば問題ないのですが、ユーザーの操作によって「1月10日〜2月24日のデータを集計してソートしてページングする」のように操作次第で柔軟な集計が求められるとなると、今回のケースには合わないかなと。
福井:なるほど、良い知見ですね。
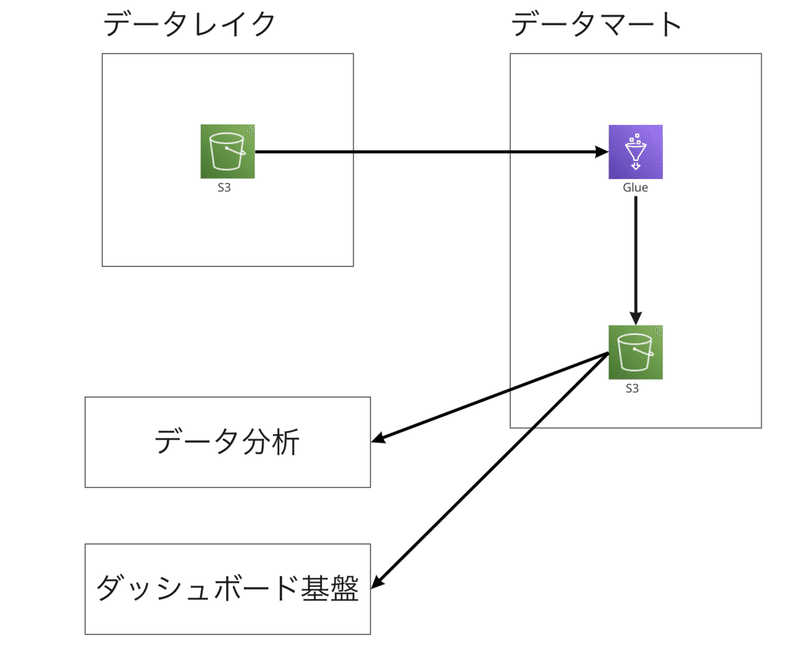
森:データレイクやRDBに溜まったログなどは、AWS Glueでデータを集計して加工したものをS3に保存しています。保存したS3のデータを、ダッシュボード基盤やデータ分析系のサービスで取得して使用しています。
▲Grafanaのダッシュボード(※ 公式のデモ画面です)
森:あとはリアルタイムダッシュボードというPVやアクセスログをリアルタイムで閲覧できる社内ツールがあるのですが、こちらはInfluxDBとGrafanaで開発しています。
福井:リアルタイムダッシュボードはAWSのマネージドサービスを使わずに、自前でやってる感じですか?
森:そうです、そうです。
社内全体でデータ活用ができる状態を目指す
福井:データ基盤系の開発ってバックエンドもフロントエンドも知識を求められるので、総合格闘技感がありますよね。学ばなきゃいけないことが多い。
森:そうですね。インフラ、データベース、サーバーサイド、フロントエンドと触る機会があるので、広範囲に知識があったほうが開発しやすいかもしれません。
福井:そのあたりは大変なところでもあり、データ基盤の面白味のある部分でもありますね。
今、なにか開発で抱えている課題ってありますか?
森:データのありかがわかりにくくなってしまっているのは直していきたいと考えています。「どういう条件で集計されたデータなのか」を把握するの難しいため、他チームがデータを活用できないということが起こりえます。ドキュメントをちゃんと書いていくなど、何かしら整備する必要はあるなと。
福井:ドキュメントは書かなくなると逆に負債になるので難しいところですよね。
森:そこは悩みどころでもあります。
あとは運用するためのルールづくりはしていく予定です。ある程度はルールに沿って操作すれば誰でも使えるようになる状態を目指して、データのうまい活用方法を社内全体に周知していきたいと思っています。
※ こちらの記事はPodcastの内容をベースに再編した記事です。実際の音源を聴きたい方はこちら
▼エンジニアの記事をもっと読みたい方はこちら
▼noteを一緒に作りませんか?
Text by megaya